AI-first hardware with anticipatory UX
AI-first hardware with anticipatory UX
AI-first hardware with anticipatory UX

A few thoughts (work-in-progress) on AI-first hardware (glasses) with anticipatory UX:
Assumptions
Foundation models will continue to improve with virtually no ceiling on their intelligence capabilities (awareness, perception, analysis, recommendation, etc.)
A combination of local and cloud processing (via 5G, and eventually 6G) will drive inference latency down
Multiple devices (watch, mobile, etc.) become more deeply networked and the data gathered by their sensors is shared in real-time
Social barriers to adoption are far lower than in previous decades (e.g., Google Glass)
Key objectives
User adoption -> Lower barriers to adoption by establishing trust through user sovereignty & control, proactive engagement with the user, and by leveraging external consistency
Contextual awareness -> AI detects the user's current focus mode / context and adapts (it learns when to act proactively and when to suggest actions and wait for confirmation)
Multi-modal AI assistant also serves as "second brain" -> Near-instant recall of user interactions, media, insights from passive monitoring, and other metadata extend the user's memory and tailors AI interactions
User sovereignty -> The user controls the scope and rhythms of data collection, data deletion, and manages the boundaries of passive monitoring
Situational override -> Hard-coded override via low-latency invocation ensures that the user has full control over decisions
AI observability -> The user has full access to AI logic and decision-making
Form factor -> Glasses that can be worn comfortably with a long battery life
Overview
The glasses work through 5 layers that sit on top of the sensory layer:
Sensory layer – The non-negotiable substrate layer, i.e.e, user's eyes, ears, etc.
Tracking layer – Monitors directional focus (eye-tracking), pupil dilation, and other physiological inputs
AI analysis layer – Model synthesises its understanding of the user and its understanding of the external world to make decisions
Display layer – The digital overlay rendered by the device; the display level has 3 depth layers:
Foreground for priority content
Midground for secondary content
Background for visual separation from external world
Digital layer – Digital input from the external world
Analog layer – Raw input from the external world
A layer control protocol (LCP) coordinates across layers based on contextual awareness, for example:
While driving, layer 5 is given priority with minimal visual interruption from layer 3
While shopping, layers 2 and 3 are amplified, with layer 4 potentially activated by the retailer (i.e., promotional content)
While focused, layer 5 is attenuated (background noise or visual distraction) while layer 3 supports focus on the contextually-relevant object(s)
The field-of-view is divided into 4 zones:
Primary perception for main focus affordance
Peripheral perception for secondary affordances
Corner for metadata and tertiary affordances
Edge for subtle affordances of objects currently outside of the field of view
Finally, the LCP allows for a "transparency gradient" where the display opacity ranges from passthrough/transparent (it is an overlay on the external world) to opaque (the external world is overwritten). This enables novel "VR" experiences ranging from "entering an immersive, darkened cinema", to "applying a LUT to the external world", to "see through walls, x-ray-like visualizations", etc.
Anticipatory UX
When the user first puts on the device and connects there is no onboarding flow of screens and forms. Instead, the device wakes up and engages them in a conversation to get them acquainted with the interaction patterns involved (either conversational or through a virtual keyboard when the user prefers to remain quiet / private). If connecting to a foundation model from a company like OpenAI or Anthropic, the user can simply 'import memory' to get the device quickly up-to-speed on their preferences and past conversations.
The device uses front-facing cameras and a microphone to observe, detect, and analyse the user's context. This contextual awareness combined with their understanding of the user themselves, enables proactive and timely engagement (i.e., when the device prompts the user). Connection to other devices that the user provides permission to adds additional information and metadata to improve the device's understanding and anticipatory capabilities.
External consistency
To aid user adoption, similar concepts and interaction patterns can be leveraged (messages, notifications, media players, a 'browser', etc.) while the nature of the display as an augmentative layer on the external world creates a new and innovative experience.
For example, watching a video (TikTok, YouTube, Netflix, etc.) can be a primary action (with the video taking up the majority of the primary perception zone), or a secondary / peripheral action (with the video displayed outside of the primary perception zone and at a smaller scale).
Visual examples
An indicator shows you the location of a nearby connection with an affordance to get their attention

A message center overlay allows the user to quickly scan new messages in the peripheral perception zone
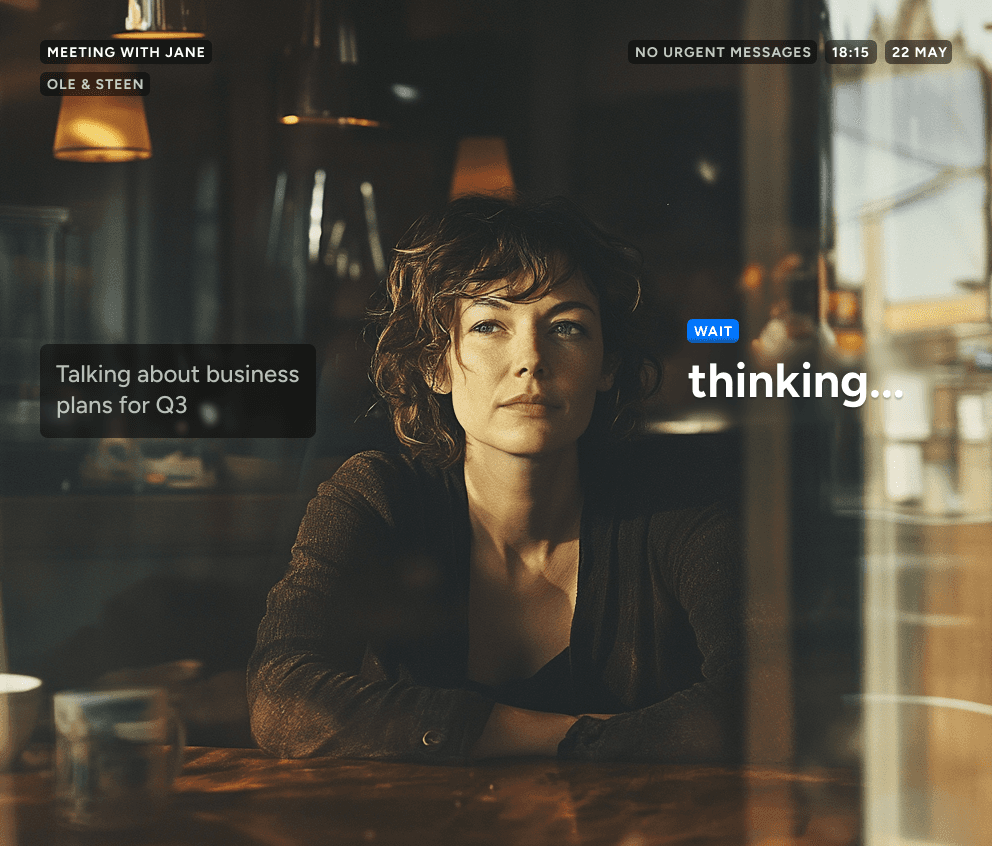
During a conversation with a colleague, affordances help the user navigate the interaction through facial cues, analysis, and keeping the main topic front-of-mind

During a journey, timely directions keep you on track, while highlighting novel/alternative locations based on proximity and the user's interests
Work-in-progress
I'll update this post as I continue working on the design
A few thoughts (work-in-progress) on AI-first hardware (glasses) with anticipatory UX:
Assumptions
Foundation models will continue to improve with virtually no ceiling on their intelligence capabilities (awareness, perception, analysis, recommendation, etc.)
A combination of local and cloud processing (via 5G, and eventually 6G) will drive inference latency down
Multiple devices (watch, mobile, etc.) become more deeply networked and the data gathered by their sensors is shared in real-time
Social barriers to adoption are far lower than in previous decades (e.g., Google Glass)
Key objectives
User adoption -> Lower barriers to adoption by establishing trust through user sovereignty & control, proactive engagement with the user, and by leveraging external consistency
Contextual awareness -> AI detects the user's current focus mode / context and adapts (it learns when to act proactively and when to suggest actions and wait for confirmation)
Multi-modal AI assistant also serves as "second brain" -> Near-instant recall of user interactions, media, insights from passive monitoring, and other metadata extend the user's memory and tailors AI interactions
User sovereignty -> The user controls the scope and rhythms of data collection, data deletion, and manages the boundaries of passive monitoring
Situational override -> Hard-coded override via low-latency invocation ensures that the user has full control over decisions
AI observability -> The user has full access to AI logic and decision-making
Form factor -> Glasses that can be worn comfortably with a long battery life
Overview
The glasses work through 5 layers that sit on top of the sensory layer:
Sensory layer – The non-negotiable substrate layer, i.e.e, user's eyes, ears, etc.
Tracking layer – Monitors directional focus (eye-tracking), pupil dilation, and other physiological inputs
AI analysis layer – Model synthesises its understanding of the user and its understanding of the external world to make decisions
Display layer – The digital overlay rendered by the device; the display level has 3 depth layers:
Foreground for priority content
Midground for secondary content
Background for visual separation from external world
Digital layer – Digital input from the external world
Analog layer – Raw input from the external world
A layer control protocol (LCP) coordinates across layers based on contextual awareness, for example:
While driving, layer 5 is given priority with minimal visual interruption from layer 3
While shopping, layers 2 and 3 are amplified, with layer 4 potentially activated by the retailer (i.e., promotional content)
While focused, layer 5 is attenuated (background noise or visual distraction) while layer 3 supports focus on the contextually-relevant object(s)
The field-of-view is divided into 4 zones:
Primary perception for main focus affordance
Peripheral perception for secondary affordances
Corner for metadata and tertiary affordances
Edge for subtle affordances of objects currently outside of the field of view
Finally, the LCP allows for a "transparency gradient" where the display opacity ranges from passthrough/transparent (it is an overlay on the external world) to opaque (the external world is overwritten). This enables novel "VR" experiences ranging from "entering an immersive, darkened cinema", to "applying a LUT to the external world", to "see through walls, x-ray-like visualizations", etc.
Anticipatory UX
When the user first puts on the device and connects there is no onboarding flow of screens and forms. Instead, the device wakes up and engages them in a conversation to get them acquainted with the interaction patterns involved (either conversational or through a virtual keyboard when the user prefers to remain quiet / private). If connecting to a foundation model from a company like OpenAI or Anthropic, the user can simply 'import memory' to get the device quickly up-to-speed on their preferences and past conversations.
The device uses front-facing cameras and a microphone to observe, detect, and analyse the user's context. This contextual awareness combined with their understanding of the user themselves, enables proactive and timely engagement (i.e., when the device prompts the user). Connection to other devices that the user provides permission to adds additional information and metadata to improve the device's understanding and anticipatory capabilities.
External consistency
To aid user adoption, similar concepts and interaction patterns can be leveraged (messages, notifications, media players, a 'browser', etc.) while the nature of the display as an augmentative layer on the external world creates a new and innovative experience.
For example, watching a video (TikTok, YouTube, Netflix, etc.) can be a primary action (with the video taking up the majority of the primary perception zone), or a secondary / peripheral action (with the video displayed outside of the primary perception zone and at a smaller scale).
Visual examples
An indicator shows you the location of a nearby connection with an affordance to get their attention
A message center overlay allows the user to quickly scan new messages in the peripheral perception zone
During a conversation with a colleague, affordances help the user navigate the interaction through facial cues, analysis, and keeping the main topic front-of-mind
During a journey, timely directions keep you on track, while highlighting novel/alternative locations based on proximity and the user's interests
Work-in-progress
I'll update this post as I continue working on the design
A few thoughts (work-in-progress) on AI-first hardware (glasses) with anticipatory UX:
Assumptions
Foundation models will continue to improve with virtually no ceiling on their intelligence capabilities (awareness, perception, analysis, recommendation, etc.)
A combination of local and cloud processing (via 5G, and eventually 6G) will drive inference latency down
Multiple devices (watch, mobile, etc.) become more deeply networked and the data gathered by their sensors is shared in real-time
Social barriers to adoption are far lower than in previous decades (e.g., Google Glass)
Key objectives
User adoption -> Lower barriers to adoption by establishing trust through user sovereignty & control, proactive engagement with the user, and by leveraging external consistency
Contextual awareness -> AI detects the user's current focus mode / context and adapts (it learns when to act proactively and when to suggest actions and wait for confirmation)
Multi-modal AI assistant also serves as "second brain" -> Near-instant recall of user interactions, media, insights from passive monitoring, and other metadata extend the user's memory and tailors AI interactions
User sovereignty -> The user controls the scope and rhythms of data collection, data deletion, and manages the boundaries of passive monitoring
Situational override -> Hard-coded override via low-latency invocation ensures that the user has full control over decisions
AI observability -> The user has full access to AI logic and decision-making
Form factor -> Glasses that can be worn comfortably with a long battery life
Overview
The glasses work through 5 layers that sit on top of the sensory layer:
Sensory layer – The non-negotiable substrate layer, i.e.e, user's eyes, ears, etc.
Tracking layer – Monitors directional focus (eye-tracking), pupil dilation, and other physiological inputs
AI analysis layer – Model synthesises its understanding of the user and its understanding of the external world to make decisions
Display layer – The digital overlay rendered by the device; the display level has 3 depth layers:
Foreground for priority content
Midground for secondary content
Background for visual separation from external world
Digital layer – Digital input from the external world
Analog layer – Raw input from the external world
A layer control protocol (LCP) coordinates across layers based on contextual awareness, for example:
While driving, layer 5 is given priority with minimal visual interruption from layer 3
While shopping, layers 2 and 3 are amplified, with layer 4 potentially activated by the retailer (i.e., promotional content)
While focused, layer 5 is attenuated (background noise or visual distraction) while layer 3 supports focus on the contextually-relevant object(s)
The field-of-view is divided into 4 zones:
Primary perception for main focus affordance
Peripheral perception for secondary affordances
Corner for metadata and tertiary affordances
Edge for subtle affordances of objects currently outside of the field of view
Finally, the LCP allows for a "transparency gradient" where the display opacity ranges from passthrough/transparent (it is an overlay on the external world) to opaque (the external world is overwritten). This enables novel "VR" experiences ranging from "entering an immersive, darkened cinema", to "applying a LUT to the external world", to "see through walls, x-ray-like visualizations", etc.
Anticipatory UX
When the user first puts on the device and connects there is no onboarding flow of screens and forms. Instead, the device wakes up and engages them in a conversation to get them acquainted with the interaction patterns involved (either conversational or through a virtual keyboard when the user prefers to remain quiet / private). If connecting to a foundation model from a company like OpenAI or Anthropic, the user can simply 'import memory' to get the device quickly up-to-speed on their preferences and past conversations.
The device uses front-facing cameras and a microphone to observe, detect, and analyse the user's context. This contextual awareness combined with their understanding of the user themselves, enables proactive and timely engagement (i.e., when the device prompts the user). Connection to other devices that the user provides permission to adds additional information and metadata to improve the device's understanding and anticipatory capabilities.
External consistency
To aid user adoption, similar concepts and interaction patterns can be leveraged (messages, notifications, media players, a 'browser', etc.) while the nature of the display as an augmentative layer on the external world creates a new and innovative experience.
For example, watching a video (TikTok, YouTube, Netflix, etc.) can be a primary action (with the video taking up the majority of the primary perception zone), or a secondary / peripheral action (with the video displayed outside of the primary perception zone and at a smaller scale).
Visual examples
An indicator shows you the location of a nearby connection with an affordance to get their attention
A message center overlay allows the user to quickly scan new messages in the peripheral perception zone
During a conversation with a colleague, affordances help the user navigate the interaction through facial cues, analysis, and keeping the main topic front-of-mind
During a journey, timely directions keep you on track, while highlighting novel/alternative locations based on proximity and the user's interests
Work-in-progress
I'll update this post as I continue working on the design